Er plopte laatst zomaar een idee in mijn hoofd: hoe zou een graph eruitzien van alle tags die ik hier op DNZM ooit heb gebruikt, met samenhang voor tags die vaak voorkomen of vaak bij elkaar in de buurt voorkomen?
Totaal niet, zo bleek, maar de situatie was gelukkig nog te redden, en was gelijk een mooie aanleiding om eens wat op te schonen.
Het idee
Het idee was heel simpel:
- haal de tags op uit de database
- druk ze tegen de content aan en daarna nog een keer tegen de tags, om te zien hoe vaak ze überhaupt worden gebruikt, en met welke andere tags ze worden gebruikt
- zeef dat door Graphviz heen en maak een prachtige graph waarin onderlinge samenhang in één oogopslag te zien is
- winst!
Zo'n query is ook, in de kern, niet heel moeilijk. Voor de niet-Bolt-gebruikers onder ons: ik gebruik hierbij de volgende tabellen:
bolt_taxonomybevat de tags (en categorieë, en wat je verder nog aan taxonomie gedefiniëerd hebt), met een naam, een slug (de URL-veilige naam) en een type;bolt_contentbevat de, je raad het al, content. Alle posts en pagina's;bolt_taxonomy_contentknoopt die twee aan elkaar, en bevat voor elke tag in een post een regel met de tag en de post.
Data opschonen
Maar voor ik die query bouwde, keek ik eerst eens naar de database (om even te zien welke kolommen ik moest uitlezen), en ontdekte ik Iets Bijzonders™, in technische termen ook wel "wat de fuck is dit nou weer" genoemd: de meeste tags kwamen dubbel in de tabel voor.
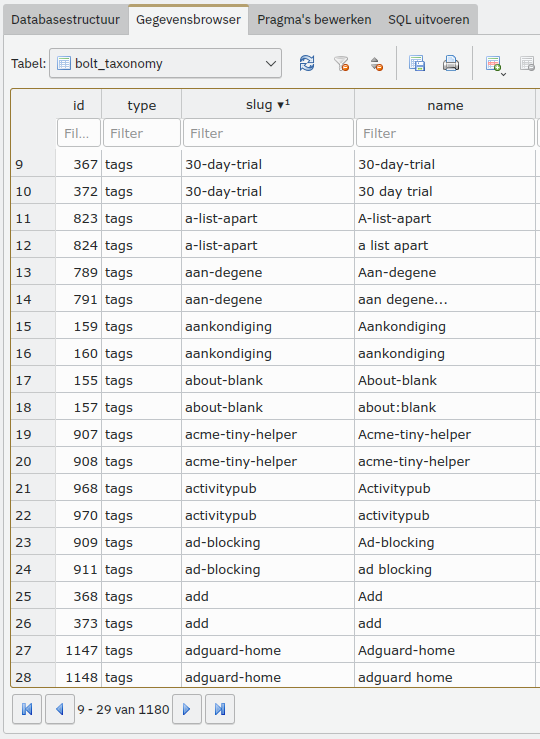
Het kwam niet voor alle tags voor, maar de meeste stonden er toch heus twee keer in. De tweede versie was dan de versie zoals ik die zou willen, de eerste... tja, waarschijnlijk met de import niet goed gegaan, of zo? Niet alle tags waren ook dubbel aan posts geknoopt, dus sommige posts hadden alleen de eerste tag, sommige alleen de tweede, en sommige allebei.
Goed, kwestie van scriptje bakken om dat recht te trekken, scriptje over de data heen trekken, dubbele tags verdwenen. Mooi. Gelijk maar een al wat langer uitstaand irritatiepuntje opgelost, en alle links in posts wat consistenter gemaakt; alle links intern hebben nu geen domeinnaam ervoor, veel handiger als ik in een testomgeving aan het rondklikken ben.
De query, en de eerste poging tot visualisatie
Met opgeschoonde data is de query dan als volgt:
SELECT bt.id, bt.slug, bt.name,
COUNT(distinct btc.content_id) content_usage,
COUNT(distinct btc2.taxonomy_id) adjecent,
GROUP_CONCAT(distinct bt2.slug) adjecent_slugs,
GROUP_CONCAT(distinct bt2.name) adjecent_names
FROM bolt_taxonomy bt
JOIN bolt_taxonomy_content btc ON bt.id = btc.taxonomy_id
JOIN bolt_taxonomy_content btc2 ON btc2.content_id = btc.content_id AND btc2.taxonomy_id != bt.id
JOIN bolt_taxonomy bt2 ON bt2.id = btc2.taxonomy_id AND bt2.type = 'tags'
WHERE bt.type = 'tags'
GROUP by bt.idDat levert een prachtig ritsje data op, een kleine 600 regels, waar ik ook een scriptje op kan loslaten om die data om te batterijen naar iets waar Graphviz mee uit de voeten kan. Zo'n bestand beschrijft alle nodes (de tags, in dit geval) en edges (hier de samenhang tussen twee tags), en zou er in het kort als volgt uit moeten zien:
strict graph {
// Elke tag wordt een "node"; naam van de node is de slug, label de name.
"delicious" [label="delicious"]
"svg" [label="svg"]
"werk" [label="werk"]
"web-2-0" [label="web 2.0"]
// etc etc
// ... en dan voor elke combinatie de twee slugs een edge:
"nokia" -- "toetsenbord"
"toetsenbord" -- "umpc"
"mechanical-keyboards" -- "toetsenbord"
"clack" -- "toetsenbord"
"thocc" -- "toetsenbord"
"keychron" -- "toetsenbord"
"gadgets" -- "toetsenbord"
// etc etc
}Resultaat is de volgende, prachtige, afbeelding:

Zoals Michael het treffend verwoordde: een gootsteenputje na het scheren. Het begin is echter hoopgevend, ik zie hier inderdaad een brei van tags, ik zie aan de randen een paar eilandjes van wat tags die ik niet vaak maar wel bij elkaar gebruikt heb, de theorie is bruikbaar.
Nu nog een bruikbare visualisatie voor elkaar krijgen.
Stoeien met data en Graphviz
Allereerst moet ik misschien proberen er wat minder data in te proppen; ik besluit om allereerst de tags eruit te filteren die maar in één post worden gebruikt. Bovendien filter ik een paar erg vaak gebruikte tags (dnzm, fwp, meta) eruit.
Dat "fwp" is sowieso een tag die ik misschien eens, inclusief posts, moet verwijderen — dat waren linkdumps uit de RSS-feeds die ik las en destijds met "feedwordpress" in mijn blog drukte. Gebruik ik al jaren niet meer, die links ontbreken, het is eigenlijk nutteloze fluff.
Los daarvan moet er duidelijk nog wat aan de visuals gesleuteld worden. Gelukkig biedt Graphviz een hele dot mogelijkheden om visualisatie van je DOT-code te beïnvloeden, en verschillende layout engines die anders met de samenhang omgaan.
Door de lettergrootte te laten schalen naarmate een tag meer samenhang heeft (ik gebruikte eerst "naarmate een tag vaker is gebruikt", maar dat clusterde minder mooi), en met kleur te werken, en de edges naar de achtergrond te drukken, en vooral te spelen met de layout, ontstaat het volgende plaatje:
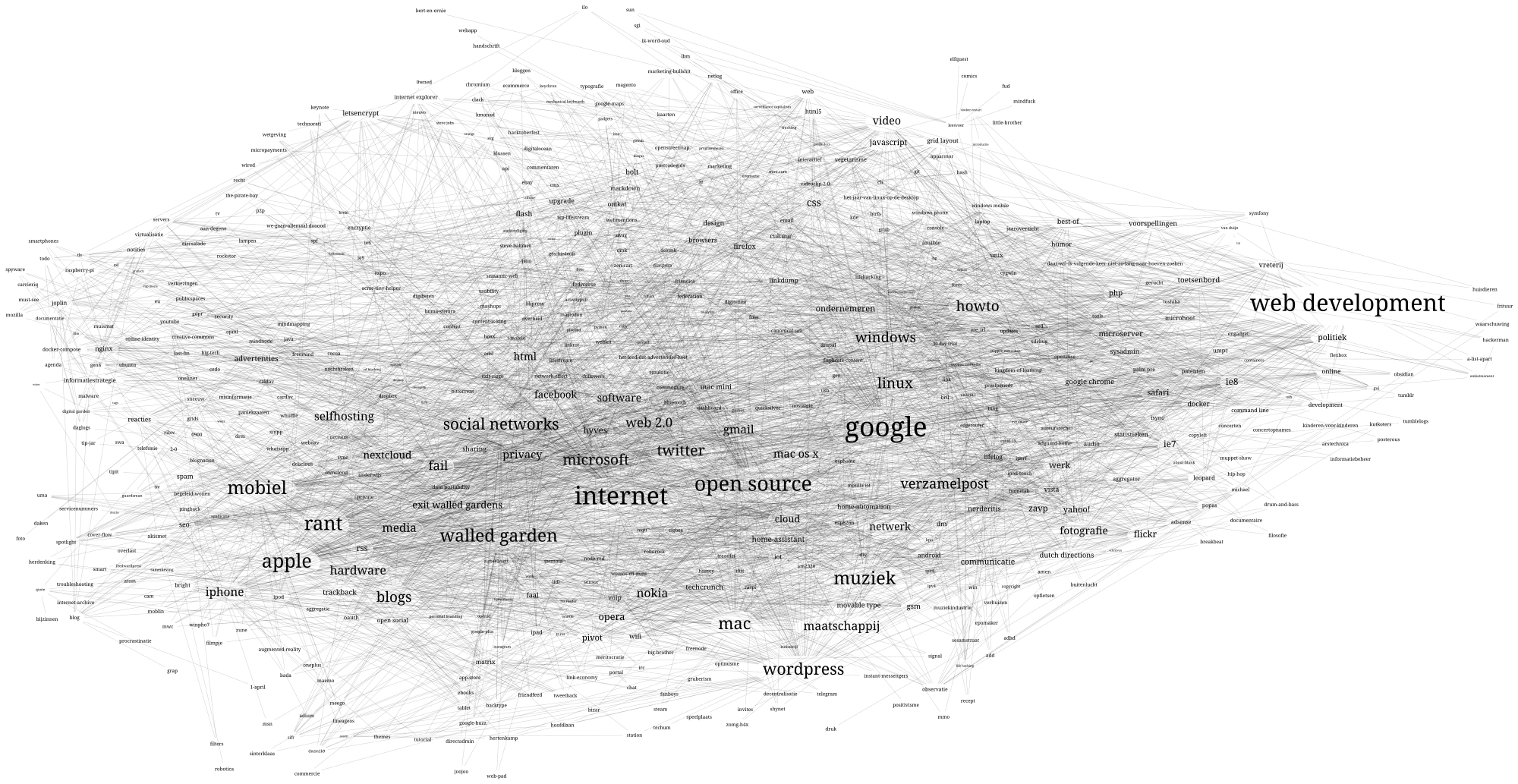
Hier zijn duidelijk een paar grote clusters te zien, met een paar tags die nog verbazingwekkend veel interlinking hebben, apple en wordpress, bijvoorbeeld. Ik schrijf daar al tijden niet zo veel meer over, maar dit is natuurlijk alle data vanaf de allereerste post.
Toch zie ik nog vaak dat er een paar gerelateerde tags een beetje bij elkaar hangen, en dat een paar andere ineens een heel stuk verderop staan, met een paar niet-gerelateerde tags ertussen gepositioneerd. Het lukt niet helemaal om de perfecte balans te vinden tussen "de graph beslaat ettelijke vierkante kilometers" en "de samenhang is overal even logisch".
Met de layout-engine sfdp, een overlap-scaling van -8 en gebogen verbindingslijntjes, en op basis van de data vanaf 2017, krijgen we een bruikbaarder beeld:
Je ziet hier veel beter de samenhang en "eilanden" van onderwerpen waarover ik de afgelopen jaren geschreven heb. Rechtsonderin de hoek "privacy en walled gardens", rechtsbovenin informatiestratiegie en blogs, linksonderin de home automation-hoek, en in het midden de host-het-zelverij en servergeneuzel. Sounds about right.
Ik denk dat ik nog een klein beetje zal blijven tweaken met de parameters, maar ik vermoed dat ik hier niet ver meer van ga afwijken.
Hoe nu verder
OK, dat is mijn nieuwsgierigheid bevredigd, plaatjes gegenereerd, prachtig, now what?
Ik ben er nog niet helemaal over uit in hoeverre dit soort grafieken een toegevoegde waarde heeft voor de gemiddelde lezer, maar voor mezelf geeft het wat meer inzicht in hoe ik tot nu toe tags gebruik, wat ik daar eventueel aan zou kunnen of willen veranderen, en hoe het zich verhoudt tot wat ik met de digitale tuin probeer te bereiken. Dat komt immers ook deels aan op het rubriceren van onderwerpen, en dat wordt met dit soort grafieken een stuk inzichtelijker.
Side note: Ik heb in Joplin ook wel eens zo'n graph-plugin gehangen, maar ik had daar nooit zo veel aan; intussen ben ik erachter dat dat vooral te maken heeft met de corpus aan tags en getagde inhoud, die in Joplin nooit zo groot was als op het blog.
Wat betreft het gebruik van tags bij posts: ik vermoed dat ik een beetje moet minderen met de hele algemene tags (zoals "meta" en "dnzm"); ik het het relatief vaak over het blog zelf, daarmee wordt het een overheersende tag. Niet dat die per definitie slecht zijn — "self hosting", "open source", "home automation" zijn prima onderwerpen — maar het draait zeker ook om de specifiekere tags eromheen.
Tegelijk triggert het ook weer een beetje de behoefte om de oude "relevante posts bij deze posts, op basis van tags" ook weer eens nieuw leven in te blazen, en mogelijk daar een variatie op dit foefje bij betrekken: ook daar zijn links, ook daar is een grafiek te maken, immers. Technisch gezien is het allemaal prima te doen...
Intussen ben ik best benieuwd of en hoe mijn medebloggers dit zouden inzetten. Medebloggers, laat u horen.
Het script
Voor de volledigheid, en voor de mensen thuis die mee willen spelen, het scriptje waarmee ik de DOT-bestanden genereer die ik door Graphviz heen jas. In een Bolt-installatie zet je het in de project-root (dus ter hoogte van public, src, var, enzovoorts), en roep je het aan met php generate-tag-graph.php | dot -Tsvg > graph.svg. Daarbij is graph.svg het resulterende bestand, voel je vrij om daar een andere naam voor te gebruiken.
Ik weet niet precies hoe de WordPress-database er tegenwoordig uitziet, maar ik zou me zo kunnen voorstellen dat het daar stiekem niet veel anders is. Uiteraard verbind je daar met een MySQL-database, maar los daarvan en los van de namen van tabellen en kolommen, zou de query en de rest van het script redelijk ongewijzigd moeten werken.
<?php
$pdo = new PDO("sqlite:var/data/bolt.sqlite");
$stmt = $pdo->query(
"SELECT bt.id, bt.slug, bt.name,
COUNT(DISTINCT btc.content_id) content_usage,
COUNT(DISTINCT btc2.taxonomy_id) adjecent,
GROUP_CONCAT(DISTINCT bt2.slug) adjecent_slugs
FROM bolt_taxonomy bt
JOIN bolt_taxonomy_content btc ON bt.id = btc.taxonomy_id
JOIN bolt_content bc ON btc.content_id = bc.id AND bc.status = 'published' AND bc.published_at > '2017-01-01'
JOIN bolt_taxonomy_content btc2 ON btc2.content_id = btc.content_id AND btc2.taxonomy_id != bt.id
JOIN bolt_taxonomy bt2 ON bt2.id = btc2.taxonomy_id AND bt2.type = 'tags' AND bt2.slug NOT IN ('meta', 'dnzm', 'fwp', 'feedwordpress')
WHERE bt.type = 'tags'
AND bt.slug NOT IN ('meta', 'dnzm', 'fwp', 'feedwordpress')
GROUP by bt.id
HAVING content_usage > 2"
);
$edges = $nodes = [];
$topAdjecent = 0;
while ($row = $stmt->fetch(PDO::FETCH_ASSOC)) {
$nodes[] = [$row["slug"], strtolower(str_replace('"', "'", $row["name"])), $row["adjecent"]];
if ($row["adjecent"] > $topAdjecent) {
$topAdjecent = $row["adjecent"];
}
foreach (explode(",", $row["adjecent_slugs"]) as $adjecentSlug) {
$edge = [$row["slug"], $adjecentSlug];
$edges[] = sprintf('"%s" -- "%s"', ...$edge);
}
$edges = array_unique($edges);
}
$nodes = array_map(
static fn(array $a) => sprintf(
'"%s" [label="%s", fontsize=%.2f, weight=%d, URL="%s"]',
$a[0],
$a[1],
14 + (($a[2] / $topAdjecent) * 30),
1 + $a[2],
"/tag/{$a[0]}"
),
$nodes
);
echo 'strict graph {
layout="sfdp"
outputorder="edgesfirst"
overlap="prism"
overlap_scaling=-8
splines="curved"
node [ color="#ffffff88", fillcolor="#ffffff88", fontname="\'Archivo Variable\', sans-serif" ]
edge [ color="#00000033" ]
'
. implode("\n ", $nodes)
. "\n\n "
. implode("\n ", $edges)
. "\n}";